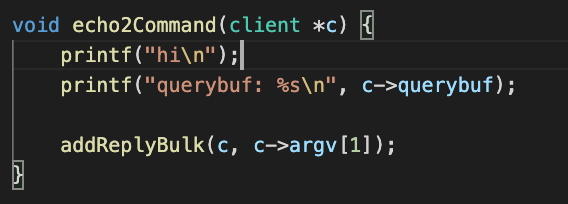
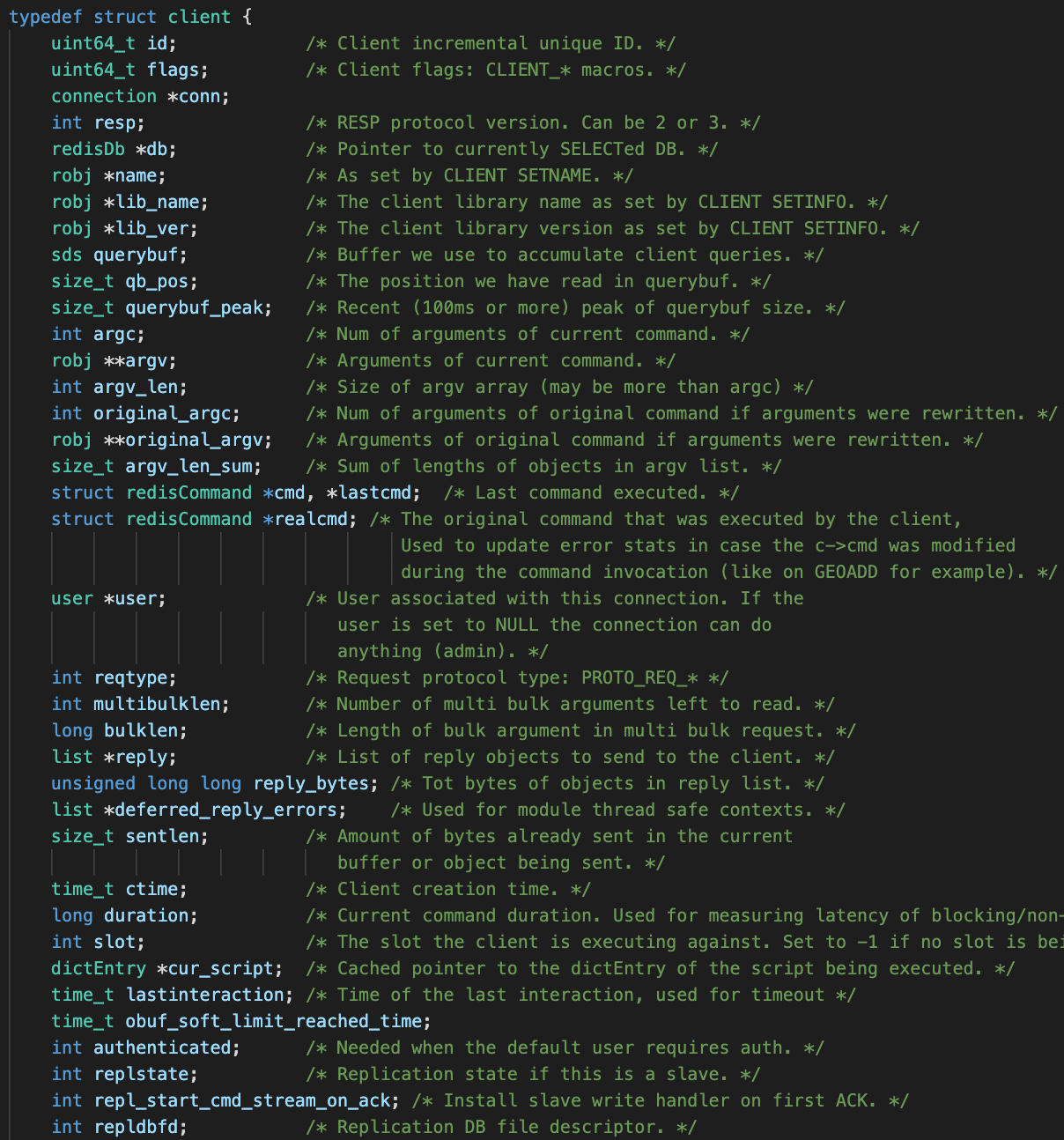
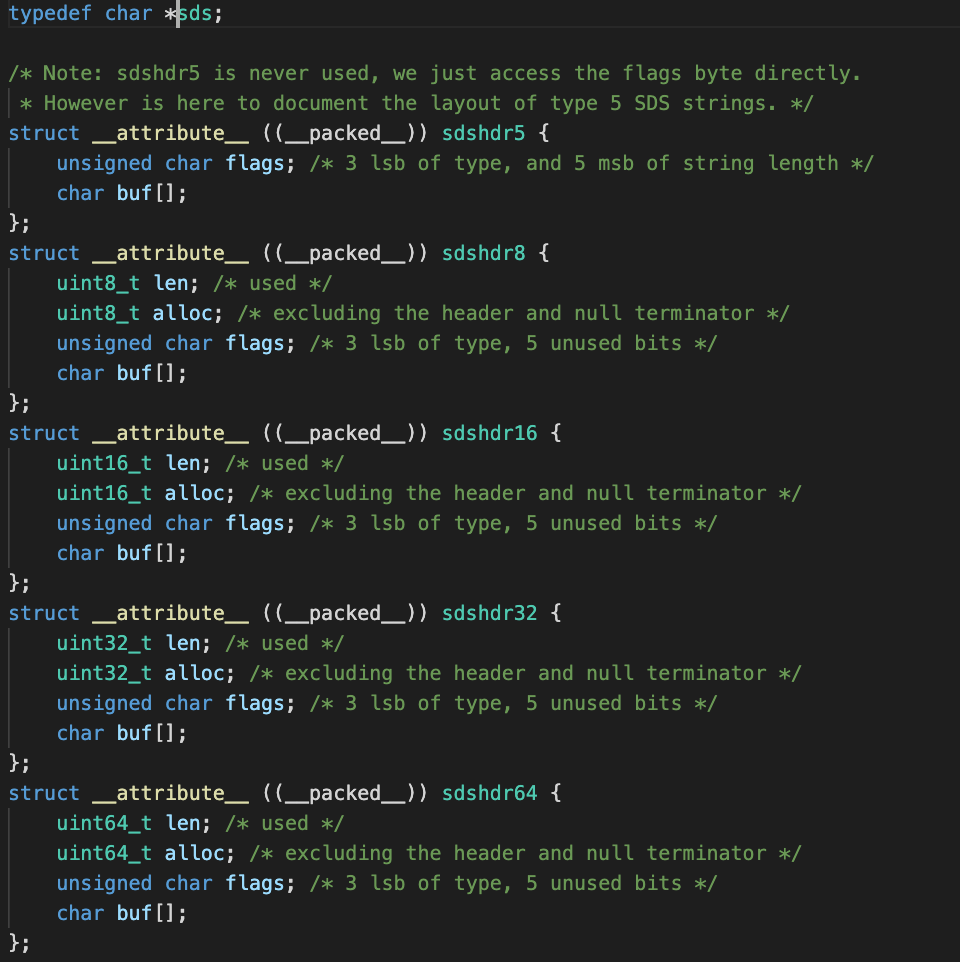
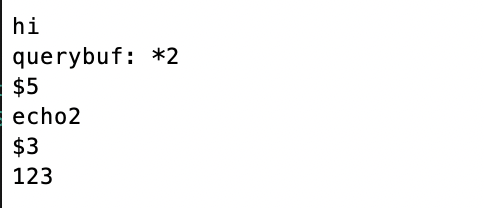프로젝트 진행 목표 및 과정
멘토님께서 Redis라는 큰 오픈소스의 이슈를 해결하기에는 4주라는 기간은 너무 짧다고 판단하여서, 해당 기간 동안 Redis에 대한 학습에 집중하기로 결정하셨습니다.
우선, 프로젝트 시작 전에 2주 동안은 오픈소스 커뮤니티에서 제공하는 유튜브 강의를 시청하여 git에 대한 기본적인 이해를 정리하는 시간을 가졌습니다. Git은 협업 및 버전 관리를 위해 필수적인 도구이며, 오픈소스 프로젝트에 기여할 때 필수적인 요소입니다. 따라서, 기본적인 Git의 개념과 사용법을 숙지하고자 이러한 학습을 진행했습니다.
다음으로, 나머지 4주 동안은 Redis에 대한 깊은 학습에 집중하였습니다. 이 기간 동안에는 Redis의 주요 기능과 용도를 학습하고, 실제로 어떻게 사용되는지에 대한 심도 있는 이해를 갖도록 노력하고 있습니다.
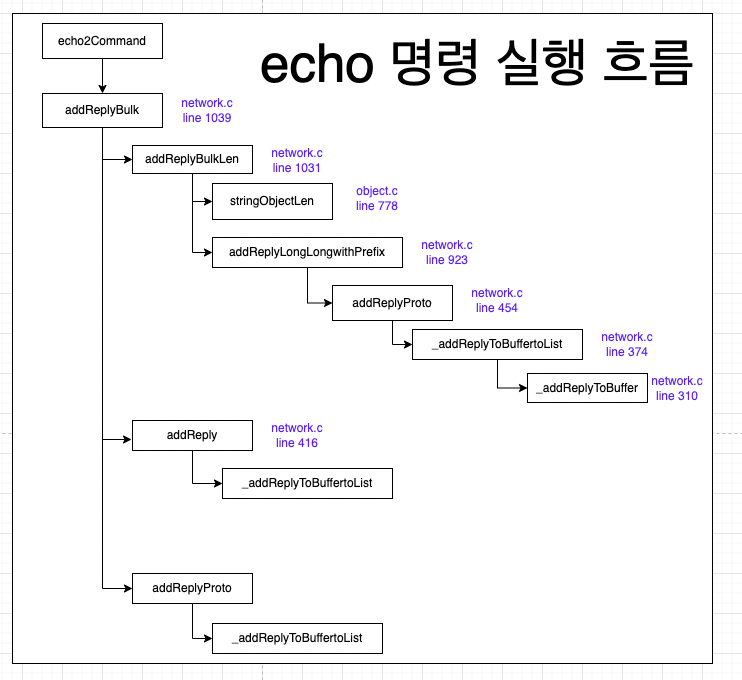
또한, Redis의 소스 코드를 분석하고 멘토님께서 주시는 과제를 수행하면서 레디스의 코드를 실제 수정하고 디벨롭하면서 실전 경험을 쌓고있습니다. 이를 통해 오픈소스 프로젝트에 기여하는 데 필요한 기술과 지식을 획득하고, 더 나아가 Redis와 관련된 이슈를 해결하는 데 기여할 수 있는 역량을 키우는 것이 목표입니다.
이러한 과정을 통해 Redis에 대한 전문 지식을 쌓고, 오픈소스에 기여할 수 있는 능력을 키우는 것이 이 프로젝트의 목표입니다. 더불어, Git을 활용한 협업 및 버전 관리에 대한 이해도 함께 높이고자 합니다. 이를 통해 프로젝트 진행 과정에서 필요한 기술과 역량을 갖추어, 효과적으로 오픈소스 프로젝트에 기여할 수 있는 개발자로 성장하는 것이 최종 목표입니다.
온⸱오프라인 모임을 통한 기여 및 활동 내역
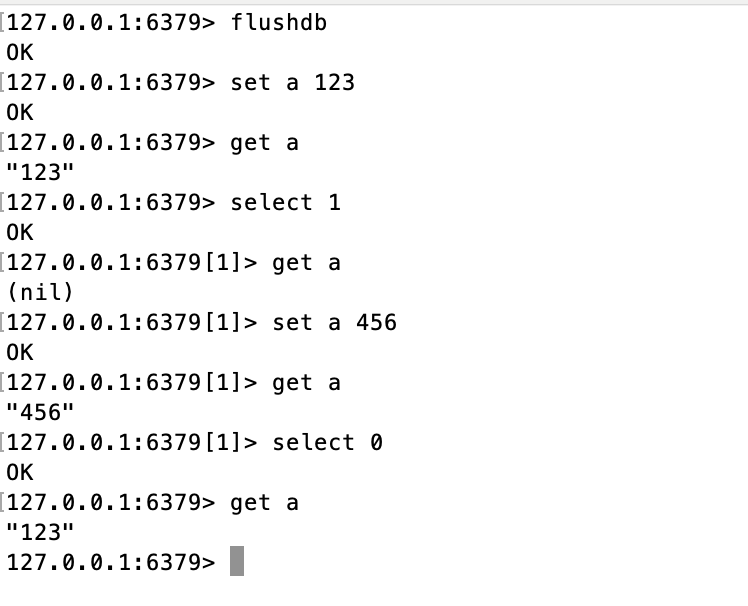
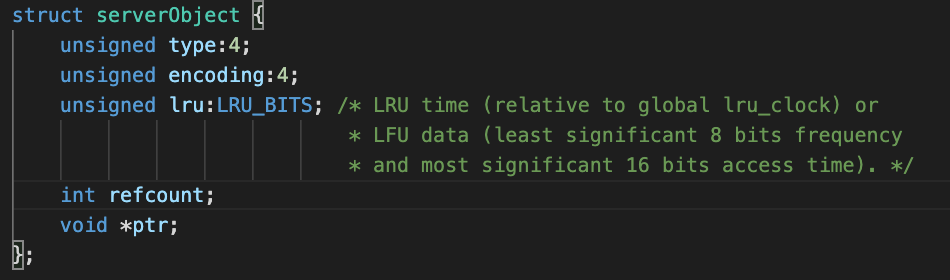
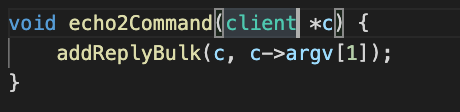
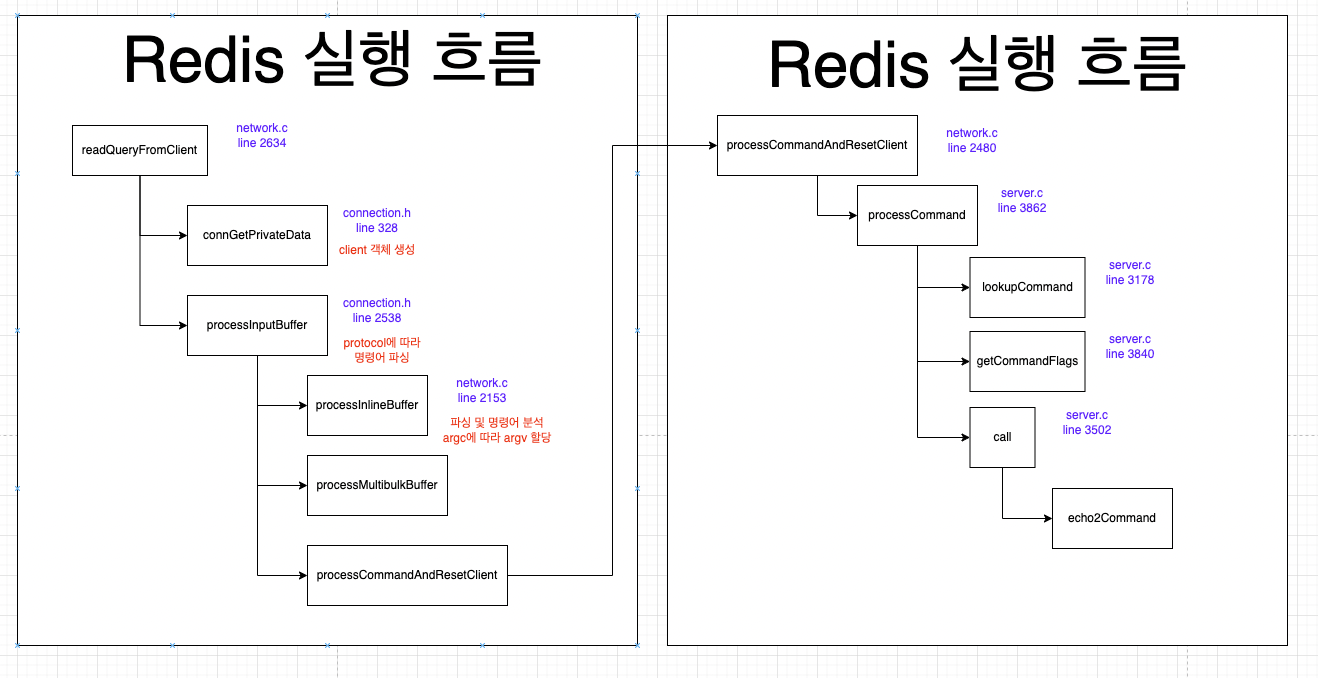
Redis의 개념을 잘 모르기에 멘토님이 말씀해주시는 것을 기록하고 그 이외의 파생해서 조금 더 공부가 필요한 것은 따로 공부해서 정리하였습니다.
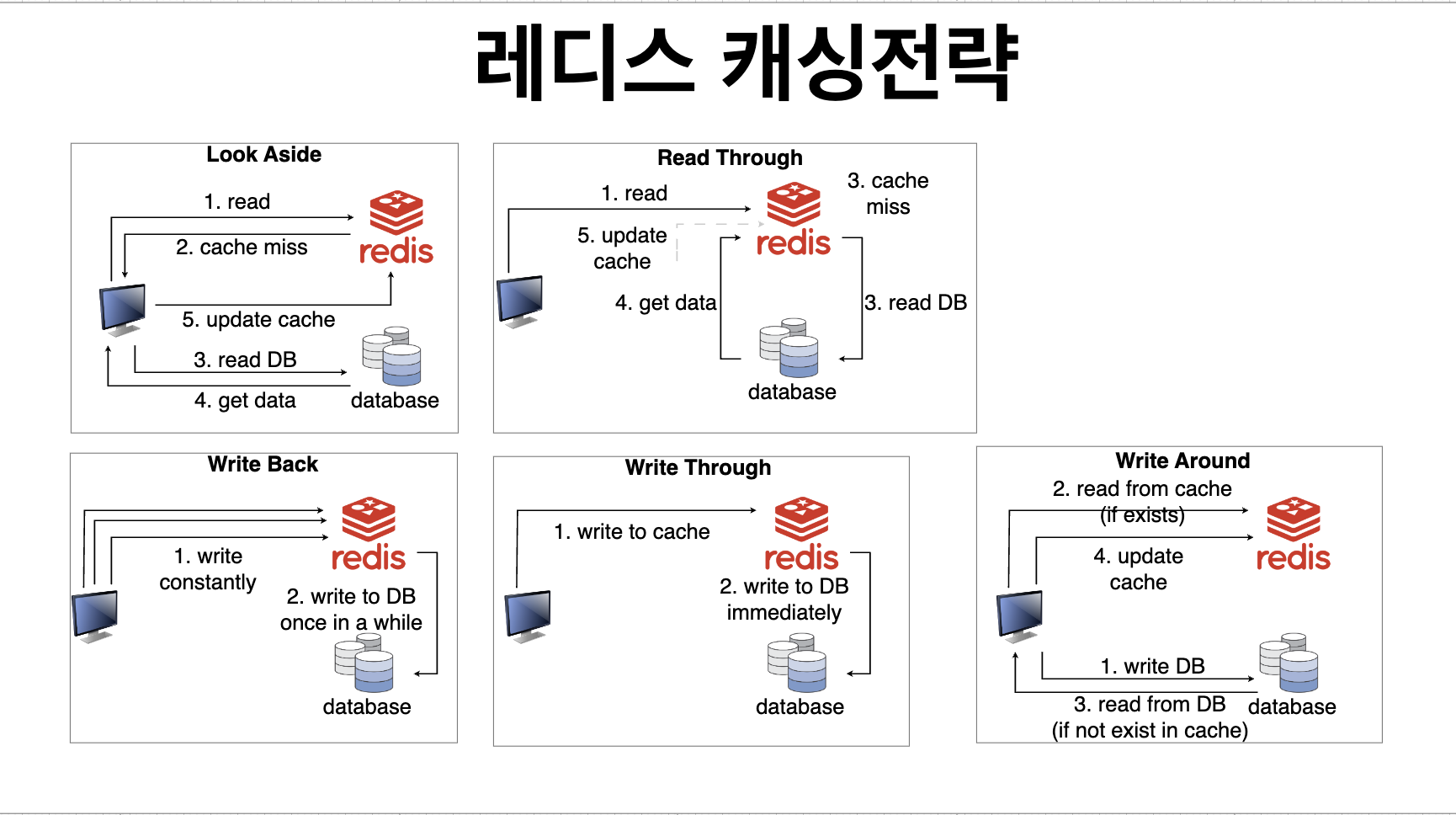
💡
2주차 온라인 미팅: https://dev-hiro.tistory.com/13
NoSQL: https://dev-hiro.tistory.com/10
과제3: https://dev-hiro.tistory.com/9
과제3 해설: https://dev-hiro.tistory.com/11
과제4: https://dev-hiro.tistory.com/14
활동소감
이 강의를 통해 DB와 같은 개념은 이론적으로만 알고 있었던 저에게 실제 코드 레벨에서의 이해와 적용 방법을 배울 수 있어서 매우 유익했습니다.
레디스는 많은 기업에서 사용되는 인메모리 데이터 구조 저장소로서, 그 유연성과 뛰어난 성능으로 유명합니다. 그런데도 실제로 그 내부 동작 메커니즘을 알고 코드 레벨에서 어떻게 활용할 수 있는지에 대해 배우는 것은 새로운 경험이었습니다. 이를 통해 레디스가 어떻게 작동하는지에 대한 이해가 더 깊어졌고, 이를 통해 개발 프로젝트에서 레디스를 보다 효율적으로 활용할 수 있을 것 같습니다.
특히, 이러한 강의를 통해 오픈소스에 대한 기여에 대한 관심이 더 커졌습니다. 다음에는 Redis에 대해 더 깊게 공부하고, 커뮤니티에 기여하는 것이 목표입니다. 오픈소스 프로젝트에 참여함으로써 다른 사람들과 지식을 공유하고 성장할 수 있는 기회를 얻을 수 있을 것으로 기대됩니다.
또한, 이를 통해 제 개인적인 기술 스택을 향상시키고, 전반적인 개발 커리어에 도움이 될 것으로 기대됩니다.
앞으로 Redis를 더 깊게 공부하고 기여하는 과정에서 어려움이 있을지도 모르지만, 그 과정에서 더 많은 것을 배우고 성장할 수 있는 기회라는 것을 인식하고 있습니다. 다양한 프로젝트와 커뮤니티에서의 경험을 통해 개발자로서의 역량을 향상시키고, 다른 이들과 함께 협업하며 성공을 이끌어 나갈 수 있기를 기대합니다.
이러한 강의를 열어주신 Open Up에 감사드리며, Redis 강사님이신 강대명 멘토님께도 감사드립니다.
'Database > OSSCA2024' 카테고리의 다른 글
| [OSSCA2024] Redis 자료구조 - 5주차 온라인 미팅 (0) | 2024.05.21 |
|---|---|
| [OSSCA2024] 과제 4 해설 (0) | 2024.05.08 |
| [OSSCA2024] Redis 과제4 실패.. (0) | 2024.05.06 |
| [OSSCA2024] Cache - 2주차 온라인 미팅 (1) | 2024.05.02 |
| [OSSCA2024] 3주차 Redis 과제 3번 해설 (1) | 2024.04.30 |